

Gemma 3 Is Here — Google's Open-Source LLMs Just Got a Big Upgrade
A complete comparison of Gemma 1, 2, and 3 — model sizes, architecture changes, multimodal support, context length upgrades, and what makes Gemma 3 a powerful open-source model

Earlier in March, Google released Gemma 3, the newest release in its open-source LLM series — and it's a significant leap over its predecessors!
In this article, we will cover:
Major upgrade points of Gemma 3 over its predecessors
Technical detail of Gemma 3
Knowledge recap — knowledge distillation
Knowledge recap — quantisation
Benchmark performance of Gemma 3
How to use image as inputs with Gemma 3?
Gemma 1 and 2 recap
Final thoughts

Strong performance with practical model size
Gemma 3 is available in 1B, 4B, 12B, and 27B parameter.
Despite this small model size, it significantly outperforms many larger models (The 27B is currently ranked at the 12th place, outperforming Llama3-405B, DeepSeek-V3 and o3-mini!).
Gemma 3 can fit in one single GPU for on-device inference.
The longest context window on the open-source market
The 4B, 12B, and 27B model support a 128K token context window, while 1B model supports 32K.
Multi-lingual
Support 140+ languages!
This is a major improvement from Gemma 2, which only supports English text
Multi-modal
Inputs to Gemma 3 can now include images! This enables Gemma 3 to be used for tasks such as visual Q&A, image captioning, and document analysis that includes images.

I also compiled a list of detailed breakdown for Gemma 3 for you. Enjoy!
Model Sizes
1B, 4B, 12B, 27B — all trained via knowledge distillation
However, in the paper it is not specified what teacher models are used for knowledge distillation.
Context Window
Extended to 32K tokens for 1B
Up to 128K tokens for 4B, 12B and 27B
Multimodal + Multilingual
Multimodal input via SigLIP vision encoder
Multilingual support, a big shift from Gemma 1 & 2
Architectural Highlights
Optimised local/global attention ratios
Grouped-Query Attention
Pan & Scan — a technique to reduce visual artifacts in image processing
Tokenisation
Still based on SentencePiece, but now with:
Split digits (e.g., "123" → "1", "2", "3")
Preserved whitespace
Byte-level fallback encoding for rare chars
Quantisation-aware training
Built-in QAT support for better low-precision performance
Further resources
Sigmoid Loss for Language Image Pre-Training
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints

What is quantisation?
Common format: FP64, FP32, FP16, BF16, INT8
There are a few basic data types to know to understand quantisation in LLMs. In general, model parameters are encoded in a certain data format. The most common types are:
Floating point — FP64 (64-bit), FP32 (32-bit)
BFloat 16-bit (BF16)
Integer 8-bit (INT8)
Floating point

The “floating point” format is one of the most common ways to represent numerical values in modern computers. The General structure:
Where:
s = sign bit (0 for positive, 1 for negative)
m = mantissa (fractional part)
e = exponent
bias is used to represent both positive and negative exponents
Here is a breakdown for each bit:
The total range supported by 64-bit, 32-bit and 16-bit are massively different:
64-bit: ~ ± 10^308
32-bit: ~ ± 10^38
16-bit: ~ ± 10^4
BF16
If we decrease the number of bits used in a floating point data format, the numerical range represented will vary. To keep the approximate same range for model training or inference, one can use formats such as bfloat16.
bfloat16 (BF16) is a 16-bit floating point format designed to provide speed and memory efficiency like FP16, while preserving much of the range and numerical stability of FP32.
It was introduced by Google and is widely used in deep learning hardware (like TPUs and newer CPUs/GPUs) because it strikes a great balance between performance and training stability.
Int8
Int8 (8-bit integer) is a compact numerical format that uses just 8 bits to represent whole numbers, typically ranging from -128 to 127 (signed) or 0 to 255 (unsigned). In practice, Int8 is used to represent floating point values approximately, using a transformation:
Scale: the resolution (float step size)
Zero-point: an offset that maps integer zero to the corresponding float
Post training quantisation
Post training quantisation (PTQ) is a technique used to convert a trained neural network (typically in 32-bit floating point precision, FP32) into a smaller and faster version by reducing the numerical precision of weights and activations — after training is completed.
Step 1: model training
You train a model normally in FP32 for accuracy and stability.
Step 2: quantisation
You convert:
Weights → to INT8 (or FP16)
Activations → either dynamically during inference, or using calibration data
\(x_{\mathrm{int8}} = \mathrm{round}(\frac{x_{\mathrm{float}}}{\mathrm{scale}}) + \mathrm{zeropoint}\)
Step 3: calibration [optional]
You run a small sample of input data through the model to estimate ranges (min/max) for activations.
This improves accuracy by choosing better quantisation parameters.
Quantisation-aware training
Quantisation-aware training (QAT) is a technique where a neural network is trained to be aware of quantisation effects (often during training). QAT usually simulates quantisation during training to preserve accuracy.
⚙️ How it works
🔁 Simulate quantisation during training
During forward passes, the model pretends weights and activations are low precision (e.g., INT8), but still stores and updates them in high precision (FP32).
This is done by inserting "fake quantisation" modules that simulate rounding and clamping to int ranges.
🧰 Fine-Tune with quantisation noise
The model learns to adapt to the noise introduced by quantisation.
Back-propagation and weight updates still happen in full precision, but gradients reflect the quantised behaviour.
🧠 Export fully quantised model
After training, you convert weights and activations to true lower precision (e.g., INT8).
The model is now fully quantised and optimised for deployment.
Further resources
A Visual Guide to Quantisation
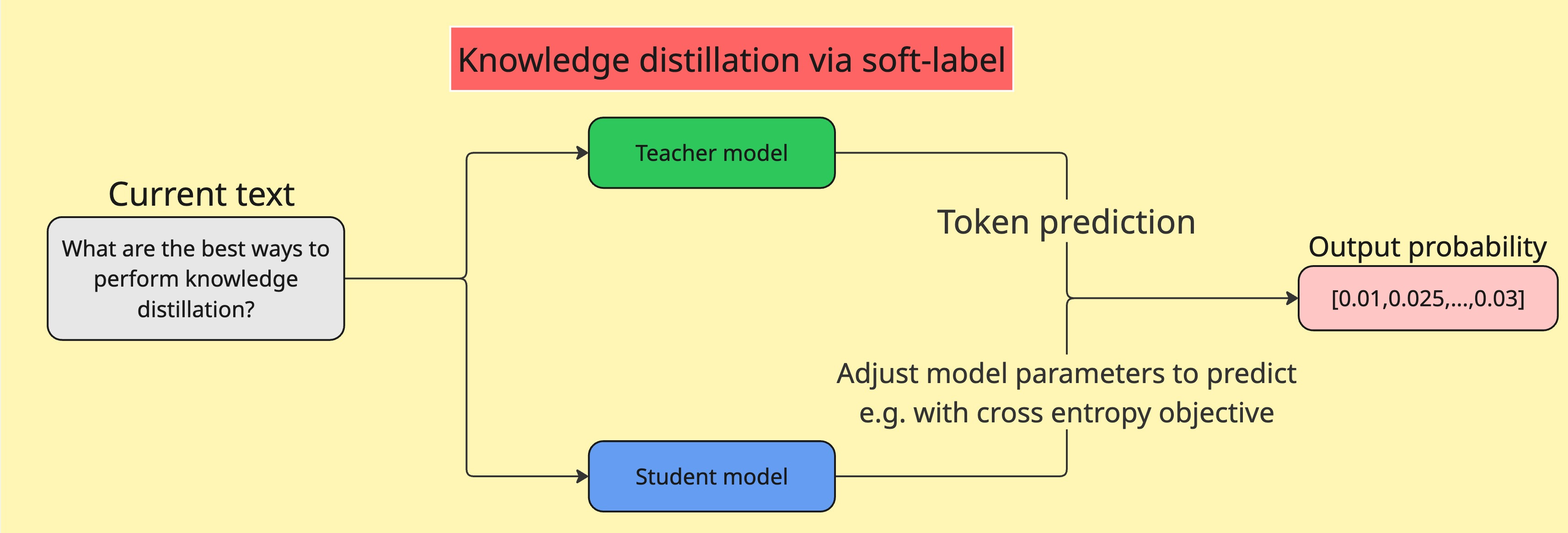
What is knowledge distillation?
Knowledge distillation is a technique where a smaller, simpler model (called the student) is trained to mimic the output of a larger, more complex model (called the teacher).
In the LLM landscape, there are two common ways to perform knowledge distillation:
Optimise the student model with token probability output from the teacher model as soft-label
Optimise the student model with text dataset prompted with the teacher model
Further resources
Distilling the Knowledge in a Neural Network G. Hinton et al. (2015)
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Victor Sanh et al. (2019)
A Survey on Knowledge Distillation of Large Language Models
X. Xu et al. (2024)
Benchmark performance
For those who are not familiar with the common LLM benchmarks, I compiled a quick summary for you below. Enjoy!
Chatbot Arena
One of the most referenced LLM leaderboards
Human preferences on AI-generated outputs
Evaluate and compare LLMs based on human preferences. Users can rank two AI-generated responses without knowing which models produced them
Developed by researchers at UC Berkeley
Performance
Gemma 3 27B ranks 12th with an Elo score of 1339, outperforming larger open models like DeepSeek-V3, LLaMA 3.1 405B, and Qwen2.5-72B!
Further resources
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
MMLU-Pro
Language comprehension and reasoning
Topics include Biology, Business, Chemistry, Computer, Economics, Engineering, Health, History, Law, Math, Philosophy, Physics, Psychology, Other
Performance
Gemma 3 27B achieves 0.676, outperforming Llama 3.3 70B!
This benchmark an enhanced version of the original Massive Multitask Language Understanding (MMLU) benchmark, designed to more rigorously evaluate the capabilities of large language models (LLMs) in language comprehension and reasoning across diverse domains.
An example of this benchmark is the following:
Question: Which of the following cases established the precedent that a defendant must be informed of the right to remain silent, the right to a lawyer, and protection from self-incrimination?
Options:
A) Brown v. Board of Education
B) Miranda v. Arizona
C) Roe v. Wade
D) Betts v. Brady
E) Plessy v. Ferguson
F) Dred Scott v. Sandford
G) Weeks v. United States
H) Gideon v. Wainwright
I) Marbury v. Madison
J) Mapp v. Ohio
Answer: B) Miranda v. Arizona
Explanation: In the landmark case Miranda v. Arizona (1966), the U.S. Supreme Court ruled that individuals taken into police custody must be informed of their rights to remain silent and to have an attorney present during questioning. This decision established the "Miranda rights," ensuring protection against self-incrimination under the Fifth Amendment.Further resources
LiveCodeBench
This benchmark assesses code generation capabilities on real-world coding problems from platforms like LeetCode and Codeforces.
There are four major areas: code generation, self-repair, test-output prediction and code execution
Performance
Gemma 3 27B achieves 29.7, while the score for Gemini-Flash-2.0-Exp are 31.8!
Further resources
Bird-SQL
Tests a model's ability to translate natural language questions into complex SQL queries across various domains.
Performance
Gemma 3 27B achieves 54.4, while the score for Gemini-1.5 are also 54.4!
Further resources
GPQA Diamond
This is a challenging dataset which comprises 448 multiple-choice questions across the domains of biology, physics, and chemistry, crafted by domain experts to ensure high quality and difficulty in PhD-level
Performance
Gemma 3 27B achieves 42.4, while the score for GPT-4o (0513) is 53.6%
Further resources
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
MATH
Problem-solving, reasoning, mathematics
A benchmark consisting of over 12,000 high school-level mathematical problems.
Performance
Gemma 3 27B achieves 89.0, while the score for Gemini 2.0 is 91.8
Further resources
SimpleQA & FACTS Grounding
Measures LLMs’ capacities to produce factual outputs as LLMs sometimes hallucinate
Performance
SimpleQA — Gemma 3 27B achieves only 10.0, while the score for Gemini 2.0 is 44.3!
FACTS Grounding — Gemma 3 27B achieves only 74.9, while the score for Gemini 2.0 is 82.8!
It can be seen that there is a significant performance gap between Gemma 3 and close-source models such as Gemini 2.0 for SimpleQA!
Further resources
How to use image as inputs with Gemma 3?
To use images as input with Gemma 3, Hugging Face provides a convenient way through the pipeline API using the "image-text-to-text" task. This allows you to pass a combination of images and text to multimodal variants of Gemma 3, such as gemma-3-4b-it, gemma-3-12b-it, or gemma-3-27b-it.
Here’s an example using a hosted image and a natural language prompt:
import torch
from transformers import pipeline
pipe = pipeline(
"image-text-to-text",
model="google/gemma-3-4b-it", # "google/gemma-3-12b-it", "google/gemma-3-27b-it"
device="cuda",
torch_dtype=torch.bfloat16
)
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/p-blog/candy.JPG"},
{"type": "text", "text": "What animal is on the candy?"}
]
}
]
output = pipe(text=messages, max_new_tokens=200)
print(output[0]["generated_text"][-1]["content"])Gemma 1
If you would like remind yourself about Gemma 1, here are a quick recap:
Model sizes: 2B and 7B parameters (both pre-trained & instruction-tuned)
Context length: 8192 tokens
Modality: Text-only, English-only
Highlights:
Surpassed LLaMA 2 (7B & 13B) and Mistral 7B in many language tasks
Further resources
Gemma: Open Models Based on Gemini Research and Technology
Gemma 2
If you would like remind yourself about Gemma 2, here are a quick recap:
Model sizes: 2B & 7B (via knowledge distillation), plus a 27B model (trained from scratch)
Context length: Still 8192 tokens
Modality: Text-only, English-only
Architecture Highlights:
Tokenizer: SentencePiece
The 27B model in particular brought competitive performance with efficient scaling, while keeping the architecture relatively lightweight.
Further resources
Gemma 2: Improving Open Language Models at a Practical Size

Before you go, here are the takeaways:
Gemma 3 is a major upgrade over Gemma 2
A open-source model that enables full control for fine tuning, alignment, inference, or deployment.
Competing performance, e.g. on benchmarks or human-based evaluations, even in comparison with models with much more parameters such as LLaMA 3, Mistral, and even close-source models (GPT or Gemini)
Resources
Gemma: Open Models Based on Gemini Research and Technology